
自动创建数据库以发现材料 无奈中的创新
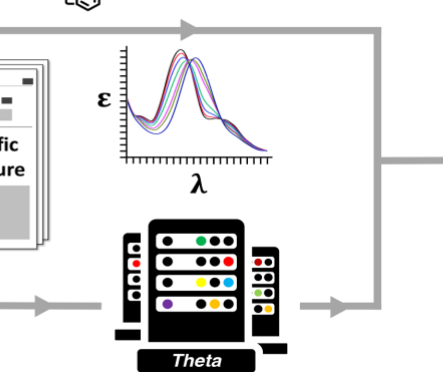
剑桥大学和阿贡大学之间的合作开发了一种技术,该技术可以使用人工智能 和高性能计算来生成自动数据库,以支持特定科学 领域。
即使在数据驱动的发现曙光后,对于科研人员来说,在大量的科学文献中搜索信息的点点滴滴以支持一个想法或找到解决特定问题的关键一直以来都是繁琐的工作。
杰奎琳·科尔非常了解演习。她是英国剑桥大学分子工程系的负责人,她在职业生涯中的大部分时间都在寻找具有光学特性的材料,这些材料可以使自己更有效地收集光,例如有一天可以为太阳能窗户提供动力的染料分子。
使用ALCF的Theta超级计算机,通过双重实验和计算化学数据途径自动生成紫外可见(UV-vis)吸收光谱数据库。(图片由Jacqueline Cole和Ulrich Mayer /剑桥大学提供。)
她回忆说:“我知道很多信息在整个文献中都是非常零散的形式。” “但是,如果您在成千上万的文件整理,那么你可以形成自己的数据库。”
因此,剑桥大学和美国能源部(DOE)的阿贡国家实验室(Argonne National Laboratory)的科尔和同事做到了这一点,并在《科学数据》(Scientific Data)杂志中列出了这一过程 。
“我知道很多信息在整个文献中都是非常分散的形式。但是,如果您整理成千上万的文档,那么就可以形成自己的数据库。” —剑桥大学的杰奎琳·科尔
科尔说,该论文描述了如何使用自然语言处理(NLP)和高性能计算来建立数据库,而高性能计算的大部分工作是在美国能源部 科学用户办公室Argonne Leadership Computing Facility(ALCF)进行的。 。
使数据库独特的因素包括项目的规模以及该事实包括有关两种材料结构的实验数据和计算数据,这些数据描述了事物的原子或化学基础,以及材料特性,这些特性提供的功能。不同的结构。
“这可能是在如此大规模数据库的第一个这样的汇编,以 5,380 像对像对实验和计算的数据,”科尔说。“而且因为它是这样一个大量,它可以作为其本身的存储库,真正打开大门,预测新的材料。”
许多新的大型数据库纯粹是基于计算建立的,其固有的缺点是它们无法通过实验数据进行验证。后者也许是最重要的,它提供了材料激发态的准确图像,激发态定义了电子的动态态,并用于计算材料的功能特性-在这种情况下为光学特性。
然后,这个激发态的萌芽目录可以帮助计算尚未构思的材料的特性,从而进一步扩展数据库。
“想像一下,人们希望发现一种新型的光学材料,以适应定制的功能应用,而我们的数据库不包含那种特殊的光学特性,” Cole解释说。“我们从激发态可用于在我们的数据库中的每个属性计算感兴趣的光学性能,并创建一个材料量身定制的功能。”
研究小组使用ALCF的Theta超级计算机,对提取了光学材料数据的每个结构进行了量子化学计算 ,从而创建了配对的实验结构和计算结构及其光学性质的数据库。
“其中一个最大的挑战是提取化学考生,可作为从太阳能电池的染料 400,000 篇科学论文,”阿尔瓦罗·巴斯克斯- Mayagoitia,在阿贡国家实验室计算科学部门的计算科学家。“我们开发了分布式架构,运用人工智能方法,如在自然语言处理中使用,在 ALCF的世界级超级计算机。”
为了自动提取该信息并将其存储在数据库中,团队转向了名为ChemDataExtractor的新型数据挖掘应用程序。一个 NLP 工具,它被设计为矿文本专门从化学和材料的文献,其中,科尔说,中“的信息分布在成千上万散落的文件和存在于高度分散化和非结构化的形式。”
Cole并不是手动搜索文章的人,而是将开发应用程序的动力描述为无奈之举。起初,她试图更通用 NLP 包,但他指出,“他们不只是失败,他们失败壮观。”
问题在于翻译,尽管有一些相似之处,但不是来自人类的语言立场,而是来自科学语言。
例如,作家可能会使用语音识别程序(一种NLP形式) 来记录笔记或访谈。该程序主要根据作者的声音进行训练,掌握各种模式和细微差别,并开始相当准确地进行转录。现在,接受具有外国口音的主题的采访,事情开始变得不妙。
在科尔的世界中,外语是科学,每个领域都在一个不同的国家。目前,你必须培养上只有一个节目“语言”,说化学,即使如此,你必须学会科学的特殊方言。
无机化学家可能会使用不熟悉的化学元素符号表示形式来构成公式,而有机化学家则更喜欢在插图框中编号的化学草图。通常,对于大多数采矿程序来说,很难提取其中的任何信息。
“那只是化学的一点点,”科尔说。“因为人们描述事物的方式是如此多样,在域特异性多样性是绝对关键的。”
为此,该团队的数据库是紫外线-可见(UV / vis)吸收光谱属性之一,它为寻求查找具有首选光谱颜色的材料的用户提供了一个公开可用的资源。
尽管该小组正在使用新数据库来筛选出可能替代太阳能电池中传统金属有机染料的有机染料,但他们已经将其应用瞄准了更广阔的领域。
作为预测新光学材料的机器学习方法的培训数据来源非常有用,它还可以为UV / vis吸收光谱仪的用户证明一种简单的数据检索选项 ,该工具已在全世界的研究实验室中广泛使用。表征新材料的核心技术。
“在这个项目中使用的协议已经被部署类似项目,补充说:”巴斯克斯- Mayagoitia。“例如,小组最近杠杆ChemDataExtractor和 ALCF 计算资源来产生的潜在电池化学品,以及磁和超导化合物膨胀数据库”。
光学材料数据库研究出现在文章中“ 实验的比较数据集和的计算属性 UV /可见吸收光谱在科学数据”。其他作者包括剑桥大学的Edward J. Beard,阿贡国家实验室的Ganesh Sivaraman和Venkatram Vishwanath。
在npj计算材料中已发表了一篇详细介绍其在磁性和超导材料方面的工作的论文 。含在电池材料数据库 290,000 的数据记录已经发表在 科学数据。












-

Reliance Industries在Usyield上的135个BPS价格为美元债券
2021-08-13
-

买这个rakesh jhunjhunwala库存与航空公司一起飞翔
2021-08-13
-

江苏炜耀医疗科技有限公司“无证生产医用防护口罩 、虚假标注生产日期” 被处罚款28万元
2021-08-13
-

你错过了这些IPO中的任何一个顶级共同资金射杀了inoctober吗?
2021-08-13
-

印度河大厦因增长担忧跌至逾8个月低点
2021-08-13
-

-

美光科技股票周四下跌
2021-08-13
-

美元萎缩2个月低与日元,美国税计划infocus
2021-08-13
-

【小康圆梦】高平:小小油葵撬动大产业带领群众走向致富路
2021-08-13

- 1 [商业热点]IPCA Labs降低评级与Edelweiss的Rs 440目标价格;看看投资者应该是什么
- 2 [商业热点]Infosys挑选Salil Parekh作为首席执行官和MD被尝试并测试了移动;过渡应该快速:JMFinancial.
- 3 [商业热点]监管机构在美国国债上看闪耀更多亮点
- 1 [时事评论]Mega IT股票回购:Wipro Investors Be Enyosys股东Stillput展出门口。
- 2 [环球要闻]在市场旺盛时购买哪些库存?Bofaml股票这个手利提级
- 3 [创业商讯]HDFC标准寿命股价在保险杠上市时跳跃;从ipoproice储备27%
- 4 [股票基金]Sensex,漂亮可能会测试记录高点作为选举结果显示BJP设置为Sweepgujarat
- 5 [财经资讯]顶级基金经理最爱,这个塔塔集团股票今年翻了一番; Edelweiss说'买'
- 6 [商业热点]IPCA Labs降低评级与Edelweiss的Rs 440目标价格;看看投资者应该是什么
- 7 [经济报道]感谢Infosys,TCS,SBI,RIL,ICICI银行和HDFCTWINS,第一次击中10,500次









Copyright © 2021 山西商业网 All Rights Reserved




